An introduction to the M1 Chip
20 November 2020
On November 10, 2020, Apple introduced it’s first effort to bring it’s own in-house system-on-a-chip (SoC) designs to it’s Mac lineup of computers. The intention to move to it’s own designs, first announced in June 2020, marks Apple’s transition away from Intel-based processor designs, and towards an in-house approach to vertically integrate Apple’s own processor designs into its computers. What does all of this mean? What did we have before, and why is this new design better?
At a high level, this means that Apple’s silicon design team is taking on a new challenge, moving beyond the iPhone and iPad chips it’s been designing for a decade, and integrating similar designs and architectures to the Mac.
What’s a computer anyway?
To start, let’s define the components that comprise a typical Mac. In addition to the user-facing components, like the display, keyboard, and trackpad, there’s a whole lot inside the computer that actually does the work.

Processor
We’ve got the central processing unit (CPU) or “processor” for short. This handles the main computing tasks on a computer. It sounds complicated, but it’s really no more complicated than a big, fancy calculator. Processors implement what are known as “instructions”–on your calculator, these are add, divide, multiply, and subtract, and if you’ve got a fancy calculator, exponents, integrals, and everything in between. On a processor, these aren’t really that different. There are add instructions, division instructions, multiplication instructions, and subtraction instructions, plus a few more that handle some more complicated math. If you can believe it, that’s all your computer really is doing–math. What makes a processor special is the speed at which it can perform these operations. Where a typical human will take on the order of seconds to respond to “what’s 13x24?”, a modern processor can perform this operation in fractions of a nanosecond. When people talk about “gigahertz” and “megahertz,” this is what they’re referring to–how many operations/instructions can my processor do per second?1 If my clock speed is higher, that is I can do more things in the same amount of time, then surely I’d have a faster processor! Not exactly, and see [1] for an explanation. But the reality is that we don’t have 10 GHz processors today; along the way, engineers found that there exists an upper bound on clock speed–at some point for various reasons (too much power, too much heat, and hitting limits of physics) we can’t continue to increase clock speeds.
Instead, engineers turned to a technique known as “scaling out”; if I have multiple processors, then I can do more work at the same time, since I can assign task 1 to processor 1, task 2 to processor 2, and so on. Well, this does work–to a degree. Just as any business manager knows that adding more people to a project doesn’t always increase productivity, the same is true for processors. The potential for gains in performance is limited to how parallel the task at hand is. Going back to the calculator analogy, it’s as if I was doing my math homework with two calculators. If problem 1 was calculating 2+2, and problem 2 was calculating 5+7, then I could do problem 1 with one calculator and problem 2 on another calculator, taking the half amount of time it would have taken me with just one calculator. This works because problem 1 and problem 2 don’t depend on each other. If instead my homework had problem 1 be to calculate 2+2, and problem 2 was to take problem 1’s result and multiply it by 4, I’d need to know the result of problem 1 before moving on to problem 2–regardless of whether I had two calculators. This would mean that my time to finish my homework with two calculators would be the same as if I had just one calculator. The same is true with computers–some tasks can be split quite easily among multiple processors as in the first homework scenario (this is known as parallel tasks), but some aren’t easy to split among multiple processors, and some simply can’t be split (these are serial tasks–there exists some interdependency between tasks) as in the second scenario.
We can summarize the tasks that depend on each other as a “single-threaded” workload. That is, that all of the tasks are performed using just one processor (or calculator). The independent, parallel tasks, can comprise a “multi-threaded” workload, where the tasks can be efficiently split among multiple processors (or calculators). The overarching concept here is known as “parallelism.” You should also know that the “instructions” (the add/divide/multiply/subtract functions) are more complicated than just a four function calculator, at that different companies, Intel/Apple/AMD implement potentially different instructions from each other. This comprises an instruction set architecture (ISA). There’s also the fact that all of this takes power, measured in Watts (W), and a higher wattage (watts consumed) on a given battery will result in less battery life. All of this to say, that processors are essentially bigger, more complicated calculators, but remember the above bolded terms–we’ll come back to them.
Memory
Memory is the second key component inside of a computer. Many people might intuitively understand memory as a way to store things so that we can recall those same things later–this is essentially what memory does.
A good analogy here is papers on a desk. Say I’m reading a bunch of books and taking lots of notes. If I’m currently reading the book, chances are it’s right in front of me on my desk, or in my hand holding it so I can read the text. I can only hold a couple things in my hand at any given moment, and at this moment I can only hold the book–but it’s right in front of me, so reading it is really easy (and fast!) to do (I simply glance down, and there it is)! However, let’s say I’m interrupted by an incoming phone call. I’m still “reading” the book (as in, it’s still on the top of things I need to do when I’m done with my phone call), so I simply put the book down on my desk and move it aside for the moment. When I finish my phone call, I hang up and grab the book off the side of my desk, place it in my hand, and pick up reading where I left off. This was still relatively quick to resume, but it was slower than when I had the book sitting in my hand. Let’s say though, I finish reading that book for now, and want to pick another book to read–I head on over to my bookshelf, slide the book away, and pick another book to read. Now I’ve got another book in my hand–if I wanted to return to my first book, I’d have to walk back over to my shelf, put the other book back, and grab the original book.
This is exactly what the hierarchy of memory is! In the analogy, my hand is my first level of memory–it can only hold very few things–one book at a time, but when I need to read that book, it’s right there in front of me. Placing the book on my desk is my second level of memory, I can perhaps hold a few books on my desk, but it’s a little slower to have to physically pick up the book and begin to read it. And finally, I have an entire bookshelf full of books adjacent to my desk–this is really slow (I have to walk over to it and grab the book), but I can hold maybe a hundred books on the shelves at any given time.
Memory in a computer is very much the same way. A small amount of really fast memory is accessible (L1 cache), a larger (but still small) amount of less really fast memory is accessible (L2 cache) and finally a really large, not as fast memory is accessible (RAM). The speed of the memory is inversely proportional to the capacity of the memory.
Disk
Recall the book example from above. Disk space is akin to a library–it’s huge, but it’s at least a drive (or a walk) to the nearest library branch to find the book. This makes disk space comparatively slow compared to RAM or any of the L1 or L2 cache memories.
Graphics and Other Accelerators
Graphics processors are simply really optimized calculators for graphics processing. They tend to have a much more complicated architecture that CPUs, but all you really need to know is that they’re really good for graphics intensive processing–like video games or watching high-resolution video.
Graphics processors are really just accelerators (they make graphics faster), and there is no reason that other accelerators can’t exist for other common functions on a computer–another good example is network processing! Network interface cards (NICs) are similarly just accelerators for sending data across a network.

What does any of this have to do with the M1?
With the long-winded description of modern computers out of the way, we can finally present what the M1 means for the future of computers. Since 2006, Apple has used Intel-based processors inside of its computers. Intel has been the leading processor maker (they’re processors are plenty fast) for most of recent history, but lately, their processors haven’t been scaling in performance as many (including Apple) have hoped2. Apple began shipping processors for it’s own devices in 2010, with the launch of the first-generation iPad. Johny Srouji, the former design manager of IBM’s POWER7 processor lineup, joined Apple in early 2008, presumably to begin development of the first of the A series line of processors (it takes time to build an entire chip!). Apple’s reasoning for this at the time (and still holds up well) is that mobile chip vendors at the time (Qualcomm, and others) weren’t necessarily building in the same components Apple needed to power the iPad (namely graphics performance for high resolution displays and strict power requirements for battery life). By designing it’s own chips, Apple can vertically integrate components that it knows it needs, and eliminate anything it doesn’t need. For mobile devices, like the iPhone and iPad, this is a huge win for battery life–and Apple’s efforts for mobile focus on a key processor metric–performance per watt: the measure of a given processors performance for a given metric of power (watt).

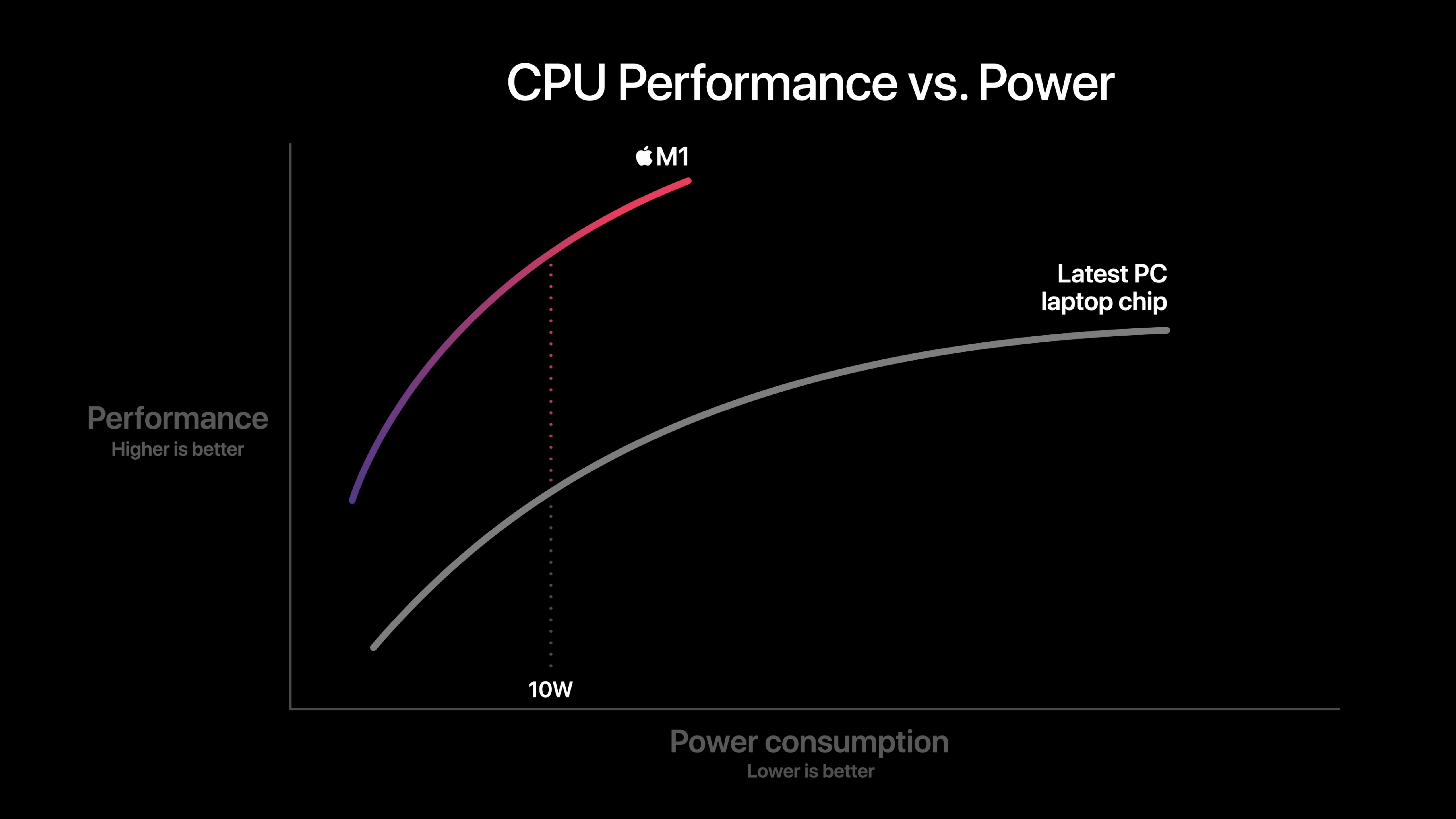
More than that just vertical integration, however, is the adoption of the ARM-architecture (Pronounced like “arm”, and an acronym for Advanced RISC Machine)3. ARM represents a processor design topology and also an instruction set architecture; recall that these are the add/divide/multiply/subtract instructions from before. The iPhone and iPad have implemented ARM-based designs since their inception in 2007 and 2010, respectively, but Mac’s had historically used Intel chips, which implement a different architecture: “x86”. The ARM ISA is distinct from the existing Intel x86 sets of instructions. When a developer codes an app, their code is eventually compiled to a specific set of processor instructions. This process, known as compilation, requires that the developer know what systems their app should run on. Once an app is compiled, it’s quite difficult to return to the original code, and as such, it’s not a trivial problem to simply translate the instructions to a different set of instructions once compiled. This presents an issue–Intel-compiled applications out-of-the-box won’t run on a non-Intel architecture processor. In short, without some sort of emulation, translation, or recompilation, Intel apps cannot run on Apple Silicon. Since many Mac developers haven’t yet recompiled their apps for the Apple Silicon (ARM) instruction set, and since Apple doesn’t have access to developers’ original source code, and emulation is proven to be fairly slow, Apple implements the Rosetta 2 Translation Layer. A deeper dive will follow in a separate post, but in short, Rosetta 2 allows Intel-compiled applications to run by translating the Intel instruction to the equivalent ARM instruction that can actually run on the processor itself. This involves an initial setup process that translates a given set of instructions located in the application binary, and then the application is good to run, with this entire process relatively invisible to the user.
ARM also implements a novel approach to processor design–the ARM BIG.little architecture. Fundamentally, when we talked about parallelization before, we simply thought of just having equal size copies of processors–two of the exact same calculator. Instead, since ARM has evolved to optimize for performance per watt, the BIG.little architecture takes a varied approach. Some tasks don’t need high performance, but some want the absolute fastest potential. Some tasks don’t need to run all the time, but others run persistently in the background all the time. ARM allows for a split–some really fast processors (but not as efficient) and some really high efficient (but not as fast) processors. It’s like having a low-powered four function calculator doing simple tasks while also using a TI-84 for intensive tasks, like mathematical integration. Each are available to the user, but at the tradeoff of speed and efficiency. These are calculators colocated on the same “die” and each instance of a calculator is called a core.
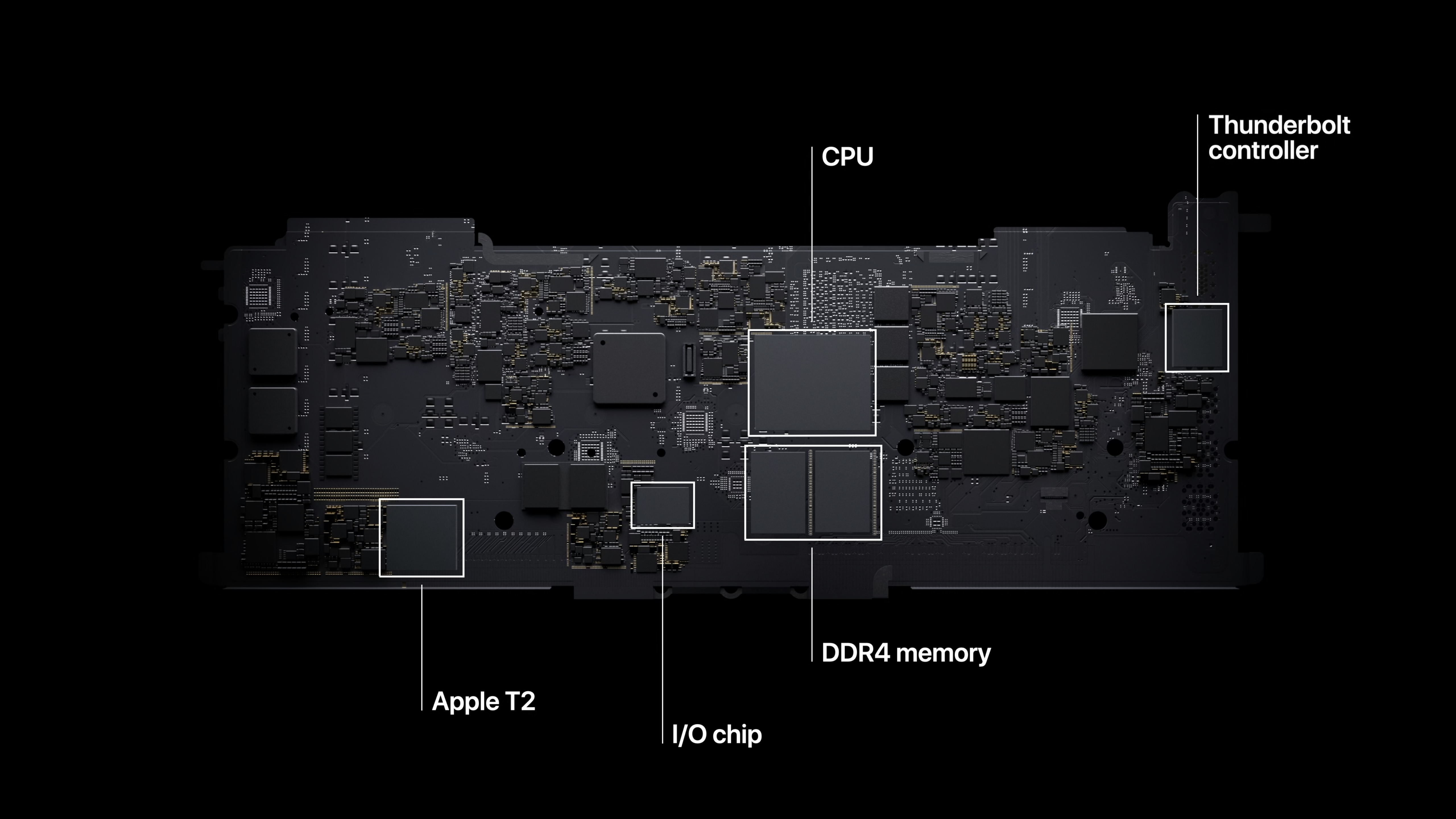
Even further, all of the above components we talked about (processor, memory, GPU) are typically separate physical pieces of hardware/silicon on a given logic board. With the M1, Apple integrates all of the components onto a single chip. Because all the components are colocated, this increases the speed at which the components can communicate and additionally decreases the power spent trying to power and access individually accessible devices. This explains a subtle design choice by Apple; in the “About this Mac” window on an M1-powered device, it lists the M1 under the label “Chip”. This is in contrast to an Intel-powered Mac, which lists the Mac’s Intel processor under “Processor”.

All of this is important to remember; When Apple touts tremendous power gains, these are the architectural differences that allow the M1 to be the most efficient Mac processor yet. The M1 powered MacBook Air has a thermal (power) design of just 10W. While this power envelope is technically equivalent to the outgoing Intel-based, Early 2020 MacBook Air4, the high efficiency of the ARM BIG.little architecture coupled with Apple’s vertical integration of hardware and software teams allows for almost double the battery life5 with the M1-powered, Late 2020 MacBook Air.
The next post will go into depth about the hardware specifics of the M1 and a few benchmarks of the M1 powered Mac mini.
[1] Sort of. The processor’s clock speed is rather the speed at which the processor can work through its own logic–1 cycle. If we have a 4 GHz processor (that’s 4 Billion cycles per second), then one cycle takes 0.25 nanoseconds (1/4E9 = 0.25E-9). The reality is that not all processors will finish exactly one instruction (add/divide/multiply/subtract) per cycle, but rather be somewhat different. This is summarized in a metric known as “Instructions Per Cycle” or IPC.
[2] There’s a lot of reasons for this that aren’t all Intel’s fault. See this article.
[3] It’s notable to point out that using ARM in notebooks or computers outside mobile phones and tablets is not a new concept. What is new is Apple carrying the gravitational pull that it does to push app developers to adopt a new architecture; Apple’s Rosetta 2 also apparently is quite performant, and allows the transition to the new ARM architecture to be slightly more manageable for those depending on Intel-compiled applications.
[4] The outgoing, Early 2020 MacBook Air is configurable to an Intel Core i7-1060NG7 processor with a TDP of 10W. The M1 in the Late 2020 MacBook Air is similarly quoted as having a 10W thermal envelope.
[5] Battery life figures comparing Early 2020, Intel MacBook Air vs Late 2020, M1 MacBook Air with a quoted runtime of 12hrs and 18hrs, respectively, of wireless web browsing